
In our last post we talked about an important Kubernetes networking construct – the service. Services provide a means for pods running within the cluster to find other pods and also provide rudimentary load balancing capabilities. We saw that services can create DNS entries within Kube-DNS which makes the service accessible by name as well. So now that we know how you can use services to access pods within the cluster it seems prudent to talk about how things outside of the cluster can access these same services. It might make sense to use the same service construct to provide this functionality, but recall that the services are assigned IP addresses that are only known to the cluster. In reality, the service CIDR isnt actually routed anywhere but the Kubernetes nodes know how to interact with service IPs because of the netfilter rules programmed by the kube-proxy. The service network just needs to be unique so that the containers running in the pod will follow their default route out to the host where the netfilter rules will come into play. So really the service network is sort of non-existent from a routing perspective as it’s only locally significant to each host. This means that it can’t really be used by external clients since they wont know how to route to it either. That being said, we have a few other options we can use most of which still rely on the service construct. Let’s look at them one at a time…
ExternalIP
In this mode – you are essentially just assigning a service an external IP address. This IP address can be anything you want it to be but the catch is that you’re on the hook to make sure that the external network knows to send that traffic to the Kubernetes cluster nodes. In other words – you have to ensure that traffic destined to the assigned external IP makes it to a Kubernetes node. From there, the service construct will take care of getting it where it needs to be. To demonstrate this, let’s take a look at our lab where we left it after our last post…
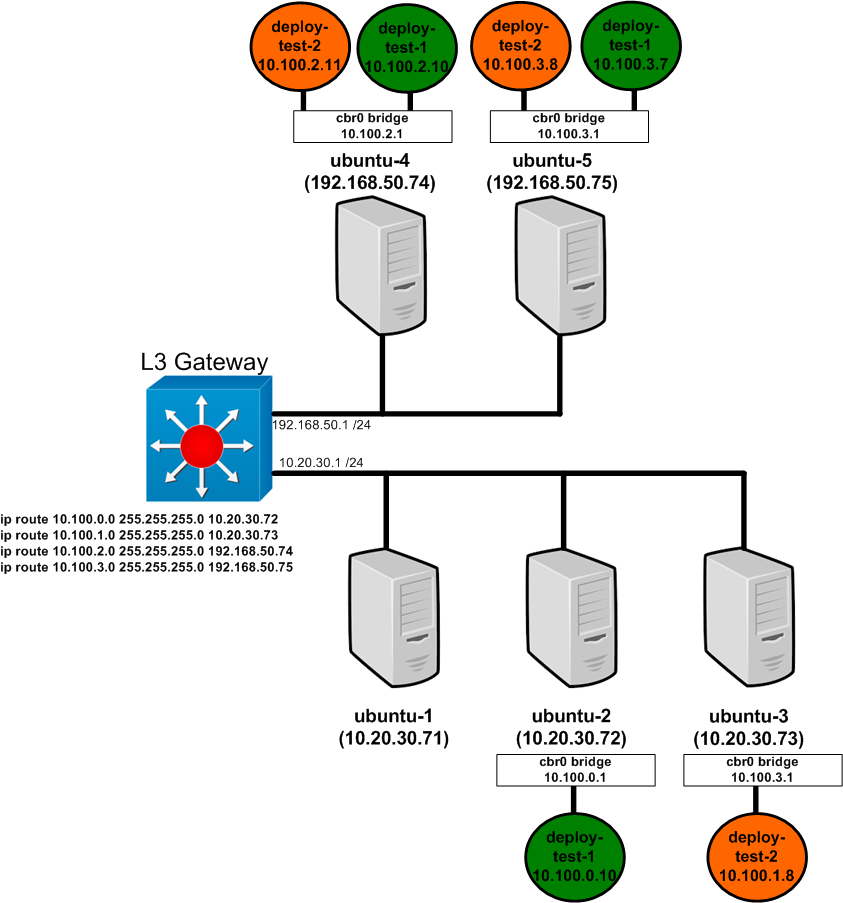
We had two different pod deployments running in the cluster in addition to the ‘net-test’ deployment but we wont need that for this example. We had also defined a service called ‘svc-test-1’ that is currently targeting the pods of the ‘deploy-test-2’ deployment matching the selectors app=web-front-end and version=v2. As we did when we changed the service selector, let’s once again edit the service and add another parameter. To edit the service use this command…
kubectl edit service svc-test-1
In the editor, add the ‘externalIPs:’ list parameter followed by the IP address of 169.10.10.1 as shown below…
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2017-04-10T16:03:24Z
name: svc-test-1
namespace: default
resourceVersion: "2178729"
selfLink: /api/v1/namespaces/default/services/svc-test-1
uid: 39f04a88-1e07-11e7-ac2c-000c293e4951
spec:
clusterIP: 10.11.12.125
externalIPs:
- 169.10.10.1
ports:
- port: 80
protocol: TCP
targetPort: web-port
selector:
app: web-front-end
version: v2
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
When done, save the service definition by closing the file as you typically would (ESC, :wq, ENTER). You should get confirmation that the service was edited when you return to the console. What we just did was told Kubernetes to answer on the IP address of 169.10.10.1 for the service ‘svc-test-1’. To test this out, let’s point a route on our gateway for 169.10.10.0/24 at the host ubuntu-2. Note that ubuntu-2 is the only host that is not currently running a pod that will match the service selector…
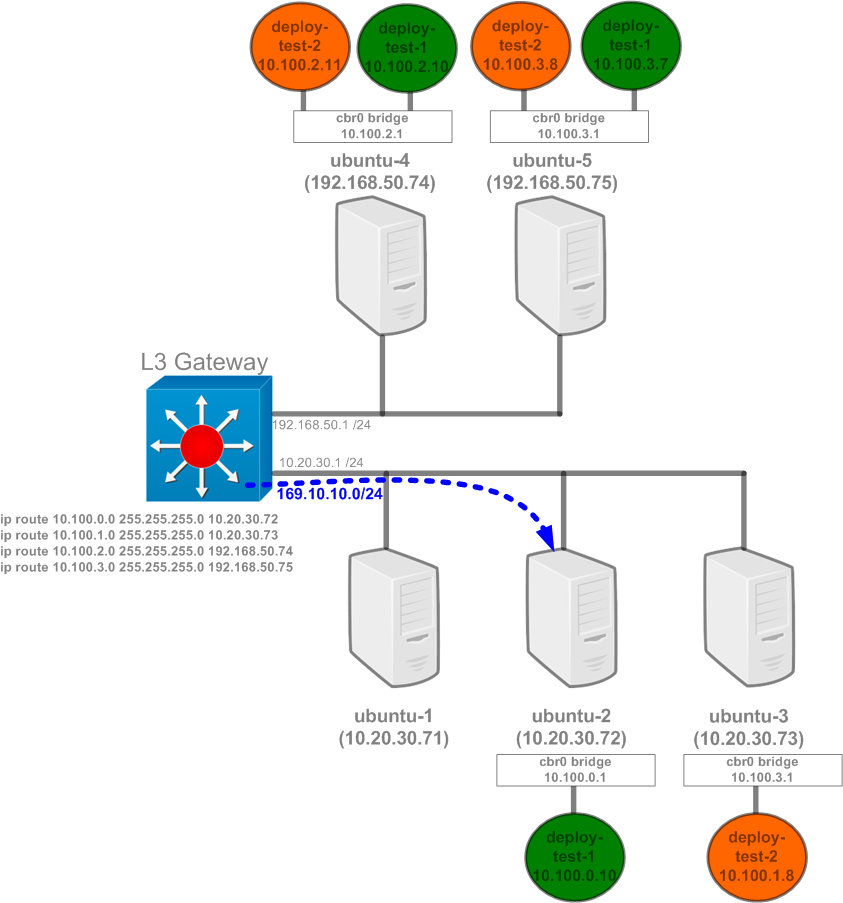
This makes ubuntu-2 a strange choice to point the route at but highlights how the external traffic gets handled within the cluster. With our route in place, let’s try to access the 169.10.10.1 IP address from a remote host…
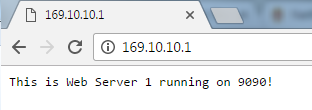
Awesome, so it works! Let’s now dig into how it works. We can assume that since services use netfilter rules, and that the IP was assigned as part of the service, that the externalIP configuration likely also uses it. So let’s start there. For the sake of easily pointing out how the exteralIPs were implemented, I took a ‘iptables-save’ before and after the modification of the service. Afterwards, I diffed the files and these three lines were added to the iptables-save output after the externalIPs were implemented in the service…
-A KUBE-SERVICES -d 169.10.10.1/32 -p tcp -m comment --comment "default/svc-test-1: external IP" -m tcp --dport 80 -j KUBE-MARK-MASQ -A KUBE-SERVICES -d 169.10.10.1/32 -p tcp -m comment --comment "default/svc-test-1: external IP" -m tcp --dport 80 -m physdev ! --physdev-is-in -m addrtype ! --src-type LOCAL -j KUBE-SVC-SWP62QIEGFZNLQE7 -A KUBE-SERVICES -d 169.10.10.1/32 -p tcp -m comment --comment "default/svc-test-1: external IP" -m tcp --dport 80 -m addrtype --dst-type LOCAL -j KUBE-SVC-SWP62QIEGFZNLQE7
So what do these rules do? The first rule is looking for traffic that is TCP and destined to the IP address of 169.10.10.1 on port 80. This has a target of jump and points to a chain called ‘KUBE-MARK-MASQ’. This chain has the following rules…
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
This rule matches all traffic and has a target of ‘MARK’ which is a non-terminating target. The traffic in this case will be marked with a value of ‘0x4000/0x400’. So what do I mean by marked? In this case ‘–set-xmarl’ is setting a marking on the packet that is internal to the host. That is – this marking is only locally significant. Since the MARK target is non-terminating we jump back to the KUBE-SERVICES chain after the marking has occurred. The next line is looking for traffic that is…
- Destined to 169.10.10.1
- Has a protocol of TCP
- Has a destination port of 80
- Has not entered through a bridge interface (! –physdev-is-in)
- Source of the traffic is not a local interface (! –src-type LOCAL)
The last two rules ensure that this is not traffic that is originated from a POD or the host itself destined to a service.
If the last two rules are foreign to you I suggest you take a look at the MAN page for the IPTables extensions. It’s definitely worth bookmarking.
Since the second rule is a match for our external traffic we follow that JUMP target into the KUBE-SVC-SWP62QIEGFZNLQE7 chain. At that point – the load balancing works just like an internal service. It’s worth pointing out that the masquerade rule is crucial to all of this working. Let’s look at an example of what this might look like if we didn’t have the masquerade rule…
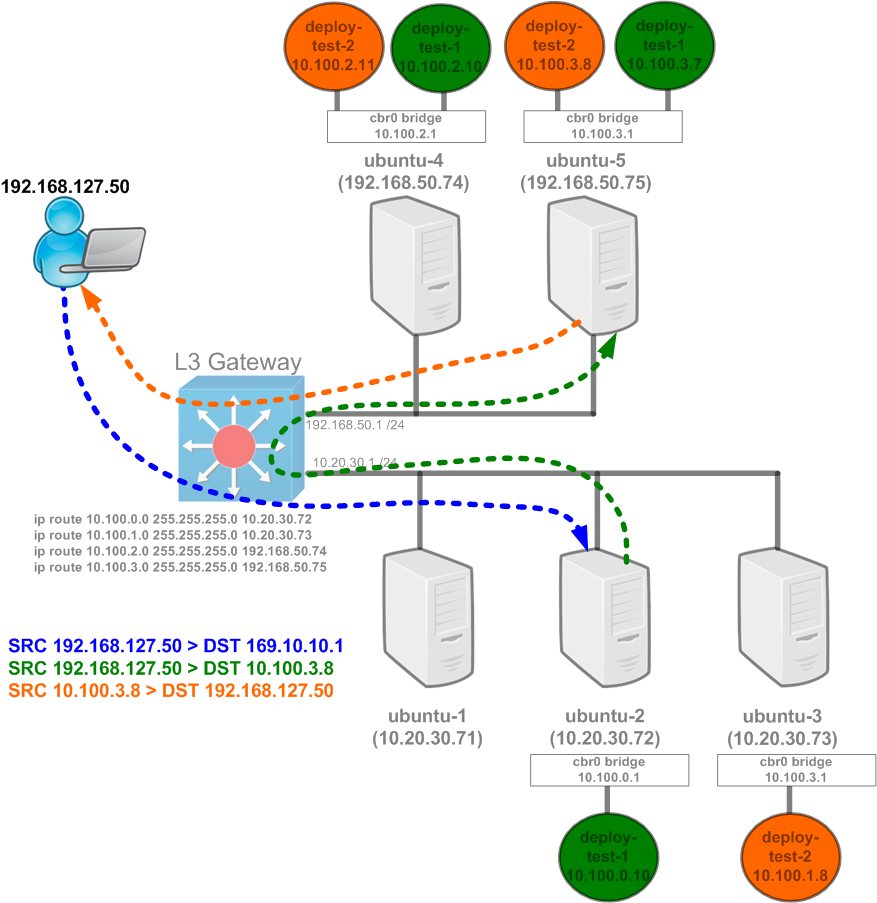
Let’s walk through what will happen without the masquerade rule shown above…
- An external user, in this case 192.168.127.50, makes a request to the external IP of 169.10.10.1.
- The request reaches the gateway, does a route lookup, and sees that there’s a route for 169.10.10.0/24 pointing at ubuntu-2 (10.20.30.72)
- The request reaches the host ubuntu-2 and hits the above mentioned IPTables rules. Without the masquerade rule, the only rule that gets hit is the one for passing the traffic to the service chain KUBE-SVC-SWP62QIEGFZNLQE7. Normal service processing occurs as explained in our last post and a pod out of the service gets selected, in this case the pod 10.100.3.8 on host ubuntu-5.
- Traffic is destination NAT’d to 10.100.3.8 and makes it way to the host ubuntu-5.
- The pod receives the traffic and attempts to reply to the TCP connection based on the source IP address of the request. The source in this case is unchanged and the host ubuntu-5 attempts to reply directly to the user at 192.168.127.50.
- The user making the request receives the reply from 10.100.3.8 and drops the packet since it hasn’t initiated a session to that IP address.
So as you can see – this just wont work. This is why we need the masquerade rule. When we use the rule, the processing looks like this…
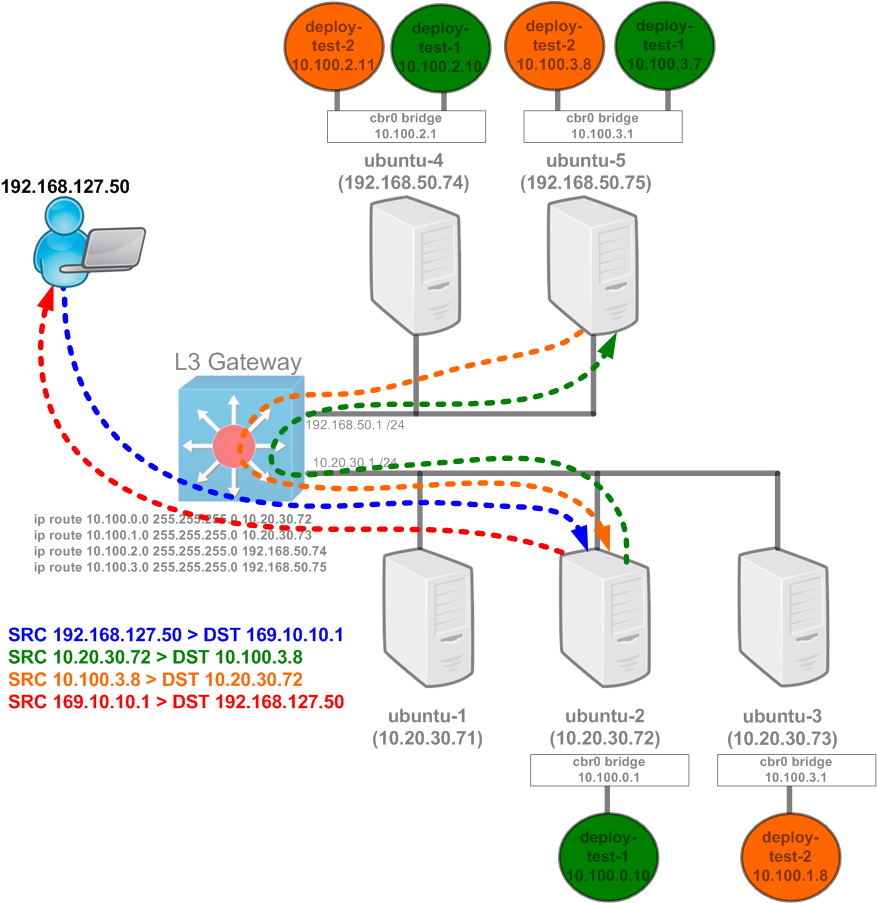
This looks much better. In this example the flows specify the correct source and destination since the host ubuntu-2 is now hiding it’s request to the pod behind it’s own interface. This ensures that the reply from the pod 10.100.3.8 will come back to the hose ubuntu-2. This is an important step because this is the host which performed the initial service DNAT. If the request does not come back to this host, the DNAT to the pod can not be reversed. Reversing the DNAT in this case means changing the source of the packet back to the original pre-DNAT source of 169.10.10.1. So as you can see – the masquerade rule is quite important to ensuring that the externalIP construct works.
NodePort
If you’re not interested in dealing with routing a new subnet to the hosts your other option would be what’s referred to as nodeport. Nodeport works a lot like the original Docker bridge mode for publishing ports. It makes a service available externally on the nodes through a different port. That port is by default in the range of 30000-32767 but can be modified by changing the ‘–service-node-port-range’ configuration flag on the API server. To change out service to nodeport we simply delete the externalips definition we inserted during the previous example and change the service type to nodeport as shown below…
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2017-04-10T16:03:24Z
name: svc-test-1
namespace: default
resourceVersion: "3471986"
selfLink: /api/v1/namespaces/default/services/svc-test-1
uid: 39f04a88-1e07-11e7-ac2c-000c293e4951
spec:
clusterIP: 10.11.12.125
ports:
- port: 80
protocol: TCP
targetPort: web-port
selector:
app: web-front-end
version: v2
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
After we save the change, we can view the services again with kubectl…
user@ubuntu-1:~$ kubectl get services -o wide NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR kubernetes 10.11.12.1 <none> 443/TCP 27d <none> svc-test-1 10.11.12.125 <nodes> 80:30487/TCP 14d app=web-front-end,version=v2 user@ubuntu-1:~$
Notice that our port column for the service now lists more than one port. The first port is that of the internal service. The second port (30487) is the nodeport, or the port that we can use externally to reach the service. One point about nodeport that I’d like to mention is that it’s an overlay on top of a typical clusterip service. In the externalip example above, notice that we didnt change the type of the service, we just added the externalips to the spec. In the case of nodeport, you need to change the service type. If you’re using a service within the cluster you might be concerned that making this change would remove the clusterip configuration and prevent pods from accessing the service. That is not the case. Nodeport works ontop of the clusterip service configuration so you will always have a clusterip when you configure nodeport.
At this point, we should be able to reach the service by connecting to any Kubernetes node on that given port…
Let’s now do a similar stare and compare with the iptables rules on each host. Once again, I’ll compare the rules in place after the configuration to a copy of the rules I had before we started our work. These are the only lines that were added to get the nodeport functionality working…
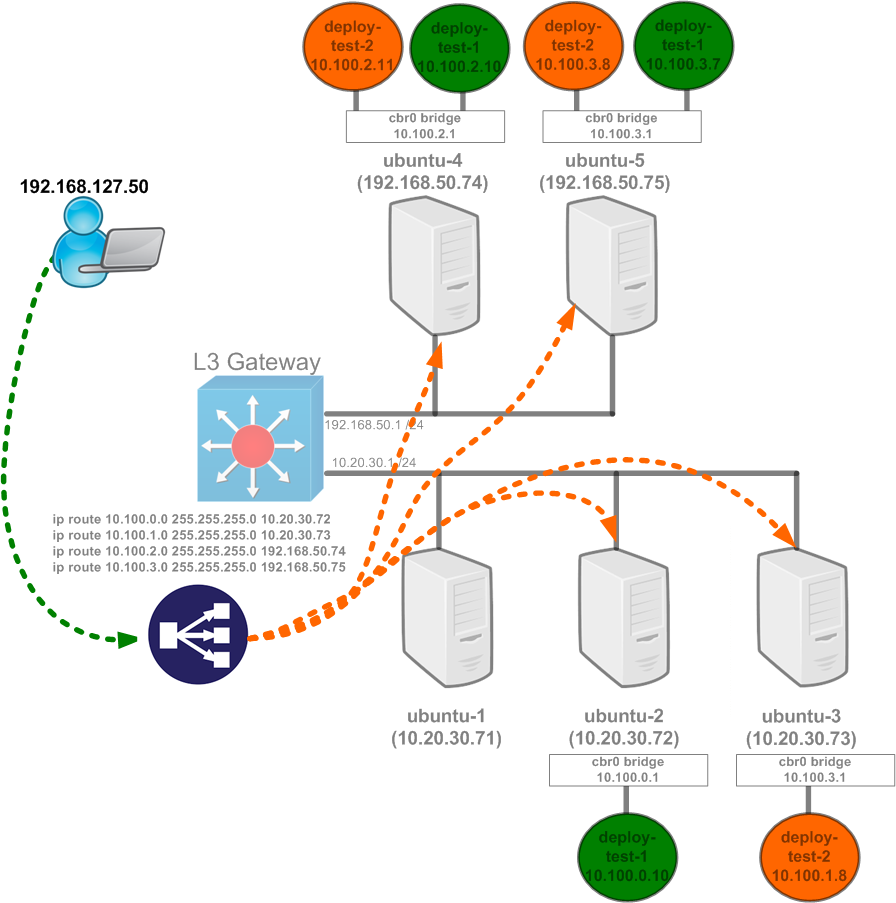
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/svc-test-1:" -m tcp --dport 30487 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/svc-test-1:" -m tcp --dport 30487 -j KUBE-SVC-SWP62QIEGFZNLQE7
These lines are pretty straight forward and perform similar tasks to what we saw above with the externalip functionality. The first line is looking for traffic destined to port 30487 which it will then pass to the KUBE-MARK-MASQ chain so that the traffic will be masqueraded. We have to do this for the same reason we explained above. The second line is also looking for traffic destined to port 30487 and when matched will pass the traffic to the specific chain for the service to handle the load balancing. But how do we get to this chain? If we look at the KUBE-SERVICES chain we will see this entry at the bottom of the chain…
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
This rule has always been present in the ruleset the chain it references (KUBE-NODEPORTS) just never existed.
Nodeport offers a couple of advantages over externalip. Namely, we can have more than one load balancing target. With externalip, all of the traffic is headed to the same IP address. While you could certainly route that IP to more than one host, letting the network load balance for you, you’d need to worry about how to update the routing when the host failed. With nodeport, it’s reasonable to think about using an external load balancer that referenced a back-end pool of all of the Kubernetes nodes or minions…
The pool could reference a specific port for each service which would be front-ended on the load balancer by a single VIP. In this model, if a node went away the load balancer could have the intelligence (in the form of a health check) to automatically pull that node from the pool. Keep in mind that the destination the load balancer is sending traffic to will not necessarily host the pod that is answering the client request. However – that’s just the nature of Kubernetes services so that’s pretty much table stakes at this point.
Lastly – if it’s more convenient, you can also specify manually the nodeport you wish to use. In this instance, I edited the spec to specify a nodeport of 30000…
apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2017-04-10T16:03:24Z
name: svc-test-1
namespace: default
resourceVersion: "3472216"
selfLink: /api/v1/namespaces/default/services/svc-test-1
uid: 39f04a88-1e07-11e7-ac2c-000c293e4951
spec:
clusterIP: 10.11.12.125
ports:
- nodePort: 30000
port: 80
protocol: TCP
targetPort: web-port
selector:
app: web-front-end
version: v2
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
Pingback: Kubernetes networking 101 – (Basic) External access into the cluster | thechrisshort
Fantastic tutorial series on kubernetes networking!
Thank you for such an in-depth clarification of the network “voodoo” that is so often just swept under the carpet of “it just does it for you.” Your packet traces, and iptables analysis really help me understand what is going on and how to make good choices about leveraging external firewalls and load balancers for enterprise workloads. Excellent diagrams and explanations. Great work!!
Im glad you found the content beneficial! Thanks for reading!
Wonderful posting!
BTW, in case of kubernetes with calico, externalIP 169.10.10.1 doesn’t working at all. Do I have to set additional information such as hostendpoint for calico node?
Excellent and detailed article