
Some time ago I wrote a post entitled ‘Kubernetes networking 101‘. Looking at the published date I see that I wrote that more than 2 years ago! That being said – I think it deserves a refresher. The time around, Im going to split the topic into smaller posts in the hopes that I can more easily maintain them as things change. In today’s post we’re going to cover how networking works for Kubernetes pods. So let’s dive right in!
In my last post – I described a means in which you can quickly deploy a small Kubernetes cluster using Ansible. I’ll be using that environment for all of the examples shown in these posts. To refresh our memory – let’s take another quick look at the topology…
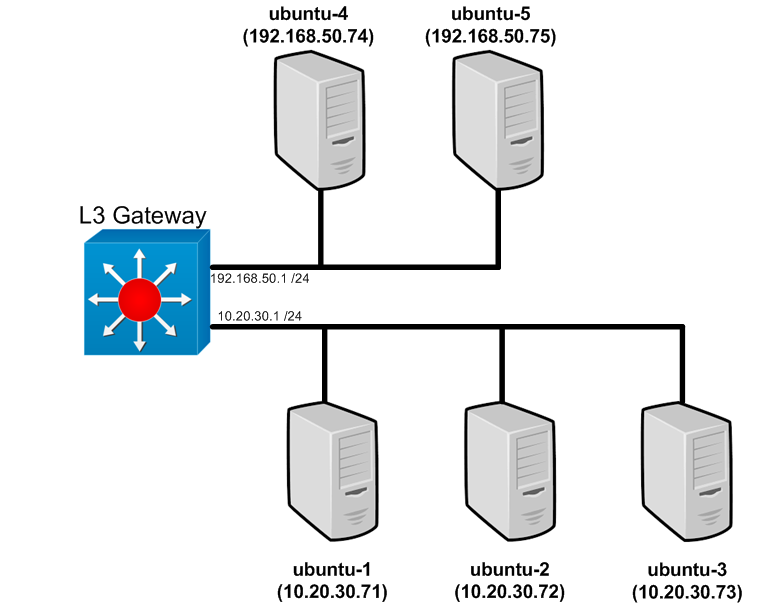
The lab consists of 5 hosts with ubuntu-1 acting as the Kubernetes master and the remaining nodes acting as Kubernetes minions (often called nodes now but I cant break the habit). At the end of our last post we had what looked like a working Kubernetes cluster and had deployed our first service and pods to it. Prior to deploying to the cluster we had to add some routing in the form of static routes on our Layer 3 gateway. This step ensured that the allocated cluster (or pod) network was routed to the proper host. Since the last post I’ve rebuilt the lab many times. Given that the cluster network allocation is random (assigned as the nodes come up) the subnet allocation, and hence the static routes, have changed. My static routes now look like this…
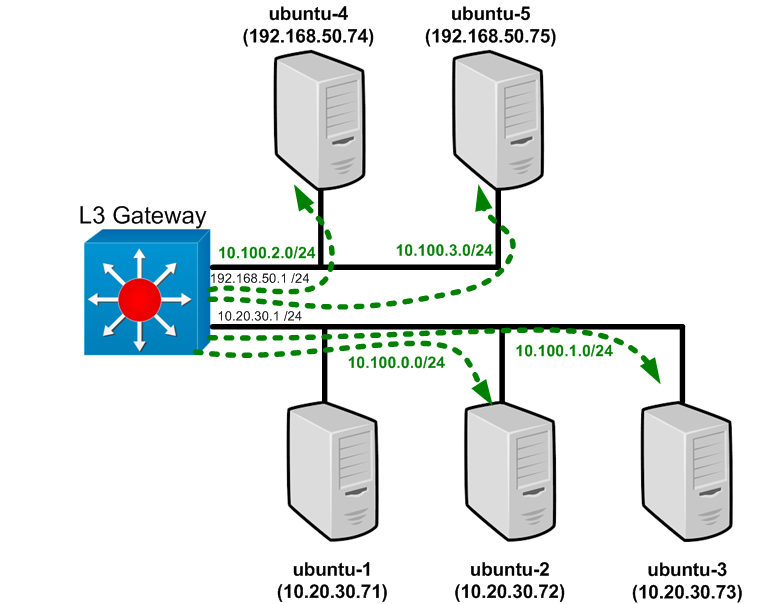
So now that we’re back to a level state – let’s talk about pods. We already have some pods deployed as part of the kube-dns deployment but to make things easier to understand let’s look at a deploying a new pod manually so we can examine what happens during a pod deployment.
I didnt point this out in the first post – but kubectl will inherently work on only your master node. It will not work anywhere else without further configuration. We’ll talk about that in an upcoming post where we discuss the Kubernetes API server. For now – make sure you’re running kubectl directly on your master.
Our first pod will be simple. To run it, execute this command on your master…
kubectl run pod-test-1 --labels="test=pod1" --image=jonlangemak/web_server_1 --port=80
What we’re doing here is simply asking the cluster to run a single container. Since the smallest deployment unit within Kubernetes is a pod, it will run this single container in a pod. But what is a pod? Kubernetes defines a pod as…
A pod (as in a pod of whales or pea pod) is a group of one or more containers (such as Docker containers), the shared storage for those containers, and options about how to run the containers. Pods are always co-located and co-scheduled, and run in a shared context. A pod models an application-specific “logical host” – it contains one or more application containers which are relatively tightly coupled — in a pre-container world, they would have executed on the same physical or virtual machine.
So while this sounds awfully application specific, there is at least one thing we can infer about a pods network from this definition. The description describes a pod as a group of containers that model a single logical host. If we carry that over to the network world, to me that implies a single network endpoint. Boil that down further and it implies a single IP address. Reading further into the description we find…
Containers within a pod share an IP address and port space, and can find each other via
localhost. They can also communicate with each other using standard inter-process communications like SystemV semaphores or POSIX shared memory. Containers in different pods have distinct IP addresses and can not communicate by IPC.
So our initial assumption was right. A pod has a single IP address and can access other containers in the same pod over the localhost interface. To summarize – all containers in the same pod share the same network namespace. So let’s take a look at a running pod and see what’s actually been implemented by running our pod. To find the pod, ask kubectl to return a list of all of the known pods. Don’t forget the ‘-o wide’ parameter which tells the output to include the pod IP address and the node…
user@ubuntu-1:~$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-test-1-2033762881-d8jgv 1/1 Running 0 16m 10.100.1.3 ubuntu-3 user@ubuntu-1:~$
So in our case the pod is running on the host ubuntu-3. You can see that the pod received an IP address out of the cluster CIDR which was previously allocated, and routed, to the host ubuntu-3. So let’s move over to the ubuntu-3 host and see what’s going on. We’ll first examine the running containers on the host…
user@ubuntu-3:~$ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 406093610e69 jonlangemak/web_server_1 "/usr/sbin/apache2 -D" 20 minutes ago Up 20 minutes k8s_pod-test-1.87f377e_pod-test-1-2033762881-d8jgv_default_2f0dbba7-13e0-11e7-ac2c-000c293e4951_26a05488 57a8f71b8c9b gcr.io/google_containers/pause-amd64:3.0 "/pause" 21 minutes ago Up 21 minutes k8s_POD.d8dbe16c_pod-test-1-2033762881-d8jgv_default_2f0dbba7-13e0-11e7-ac2c-000c293e4951_6feb94cc b957ffc0e9e0 gcr.io/google_containers/exechealthz-amd64:1.2 "/exechealthz '--cmd=" 22 minutes ago Up 22 minutes k8s_healthz.b12b3f61_kube-dns-v20-1485703853-ht85t_kube-system_040d0193-13e0-11e7-ac2c-000c293e4951_52ff2ccb 450af33774e0 gcr.io/google_containers/kube-dnsmasq-amd64:1.4 "/usr/sbin/dnsmasq --" 22 minutes ago Up 22 minutes k8s_dnsmasq.149711a5_kube-dns-v20-1485703853-ht85t_kube-system_040d0193-13e0-11e7-ac2c-000c293e4951_31c109b1 4ec95c6779df gcr.io/google_containers/kubedns-amd64:1.8 "/kube-dns --domain=c" 22 minutes ago Up 22 minutes k8s_kubedns.1a8c56db_kube-dns-v20-1485703853-ht85t_kube-system_040d0193-13e0-11e7-ac2c-000c293e4951_9a6282cd b190f2d099d7 gcr.io/google_containers/pause-amd64:3.0 "/pause" 22 minutes ago Up 22 minutes k8s_POD.d8dbe16c_kube-dns-v20-1485703853-ht85t_kube-system_040d0193-13e0-11e7-ac2c-000c293e4951_0ba916b3 user@ubuntu-3:~$
This host happens to also be running one of the kube-dns replicas so for now only focus on the top two lines of output. We can see that our container jonlangemak/web_server_1 is in fact running on this host. Let’s inspect the containers network configuration to see what we can find out…
user@ubuntu-3:~$ sudo docker inspect 406093610e69 | grep NetworkMode
"NetworkMode": "container:57a8f71b8c9b53280986a7cd31f2a232254eccedd941c34715dc9e1bbe205030",
user@ubuntu-3:~$
From this output we can tell that this container is running in what I call mapped container mode. Mapped container mode describes when one container joins the network namespace of an existing container. If we look at the ID of the container that jonlangemak/web_server_1 is mapped to, we can see that it belongs to the second container in the above output – gcr.io/google_containers/pause-amd64:3.0. So we knew that all containers within the same pod share the same network namespace but how does the pause container fit into the picture?
The reason for the pause containers is actually pretty easy to understand when you think about order of operations. Let’s consider a different scenario for a moment. Let’s consider a pod definition which specifies three containers. As we already mentioned – all containers within a single pod share the same network namespace. In order to do that, one method might be to launch one of the pod containers, and then attach all subsequent containers to that first container. Something like this…
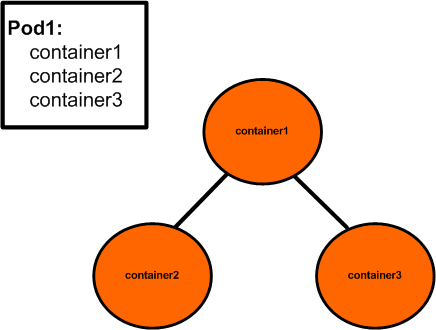
But this doesn’t work for a couple of reasons. Containers are spawned as soon as the image is downloaded and ready so it would be hard to determine which container would be ready first. However – even if we don’t consider the logic required to determine which container the others should join, what happens when container1 in the diagram above dies? Say it encounters an error, or a bug was introduced that causes it die. When it dies, we just lost our anchoring point for the pod…
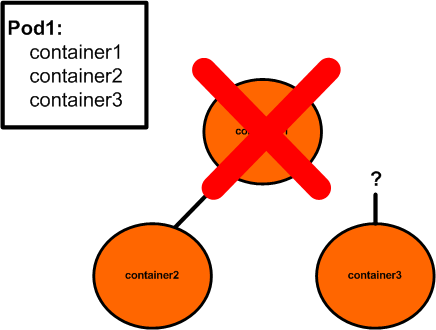
Let’s imagine container1 spawned first. After that container2 spawned and managed to connect itself to container1’s network namespace. Shortly thereafter container1 encountered an error and died. Not only is container2 in trouble, but now container3 has no place to connect to.
If you’re interested in seeing the results it’s not hard to replicate just by running a couple Docker containers on their own. Start container1, then add container2 to container1’s network namespace (–net=container:<container1’s name>), then kill container1. Container2 will likely stay running but wont have any network access and no other containers can join container1 since it’s not running.
A better approach is to run a known good container and join all of the pod containers to it…

In this scenario – we know that the pause container will run and we don’t have to worry about what container comes up first since we know that all containers can join the pause container. In this case – the pause container servers as an anchoring point for the pod and make it easy to determine what network namespace the pod containers should join. Makes pretty good sense right?
Now let’s look at an actual scenario where a pod has more than one container. To deploy that we’ll need to define a configuration file to pass to kubectl. Save this on your master server as pod2-test.yaml…
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: pod-test-2
spec:
replicas: 1
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache-web-server-1
image: jonlangemak/web_server_1
ports:
- containerPort: 80
name: web-tcp-80
protocol: TCP
- name: apache-web-server-2
image: jonlangemak/web_server_2
ports:
- containerPort: 80
name: web-tcp-80
protocol: TCP
Notice that this specification defines two containers, jonlangemak/web_server_1 and jonlangemak/web_server_2. To have Kubernetes load this pod run the following command…
user@ubuntu-1:~$ kubectl create -f pod2-test.yaml deployment "pod-test-2" created user@ubuntu-1:~$
Now let’s check the status of our pod deployment…
user@ubuntu-1:~$ kubectl get pods NAME READY STATUS RESTARTS AGE pod-test-1-2033762881-d8jgv 1/1 Running 0 2h pod-test-2-3211448557-fl5ll 1/2 Error 2 51s user@ubuntu-1:~$
Notice that pod2 lists a status of error. Instead of going to that node to check the logs manually, let’s retrieve them through kubectl…
user@ubuntu-1:~$ kubectl logs pod-test-2-3211448557-fl5ll -c apache-web-server-1 apache2: Could not reliably determine the server's fully qualified domain name, using 10.100.0.2 for ServerName user@ubuntu-1:~$ user@ubuntu-1:~$ kubectl logs pod-test-2-3211448557-fl5ll -c apache-web-server-2 apache2: Could not reliably determine the server's fully qualified domain name, using 10.100.0.2 for ServerName (98)Address already in use: make_sock: could not bind to address 0.0.0.0:80 no listening sockets available, shutting down Unable to open logs user@ubuntu-1:~$
The logs from the first container look fine but the second show some errors. Have you figured out what we did wrong yet? Recall that a pod is a single network namespace. Per our pod definition above we attempted to load two containers, in the same pod, that were using the same port number. The first one loaded successfully but when the second tried to bind to it’s defined port it failed since it overlapped with the other pod container. The solution to this is to run two containers that are listening on two different ports. Let’s define another YAML specification called pod3-test.yaml…
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: pod-test-3
spec:
replicas: 1
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache-web-server-1
image: jonlangemak/web_server_1
ports:
- containerPort: 80
name: web-tcp-80
protocol: TCP
- name: apache-web-server-3
image: jonlangemak/web_server_3_8080
ports:
- containerPort: 8080
name: web-tcp-8080
protocol: TCP
Let’s clean up our last test pod and then deploy this new pod…
user@ubuntu-1:~$ kubectl delete deployments pod-test-2 deployment "pod-test-2" deleted user@ubuntu-1:~$ user@ubuntu-1:~$ kubectl create -f pod3-test.yaml deployment "pod-test-3" created user@ubuntu-1:~$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-test-1-2033762881-d8jgv 1/1 Running 0 2h 10.100.1.3 ubuntu-3 pod-test-3-1953354478-dfhjw 2/2 Running 0 53s 10.100.2.2 ubuntu-4 user@ubuntu-1:~$
Great! Now the pod is running as expected. If we go to host ubuntu-4 we’ll see a single pause container for the pod as well as our two pod containers running in Docker…
user@ubuntu-4:~$ sudo docker ps [sudo] password for user: CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b6d37a5fac6a jonlangemak/web_server_3_8080 "/usr/sbin/apache2 -D" About a minute ago Up About a minute k8s_apache-web-server-3.8ebe4029_pod-test-3-1953354478-dfhjw_default_0fc75bbd-13f8-11e7-ac2c-000c293e4951_20ecd47b 7a4b2eed4ea9 jonlangemak/web_server_1 "/usr/sbin/apache2 -D" About a minute ago Up About a minute k8s_apache-web-server-1.db283e26_pod-test-3-1953354478-dfhjw_default_0fc75bbd-13f8-11e7-ac2c-000c293e4951_2ad523f8 fdebc46bf25c gcr.io/google_containers/pause-amd64:3.0 "/pause" 2 minutes ago Up 2 minutes k8s_POD.d8dbe16c_pod-test-3-1953354478-dfhjw_default_0fc75bbd-13f8-11e7-ac2c-000c293e4951_4496c456 user@ubuntu-4:~$
If we inspect the two pod containers we’ll see that they are connected to the pause container as expected…
user@ubuntu-4:~$ sudo docker inspect b6d37a5fac6a | grep NetworkMode
"NetworkMode": "container:fdebc46bf25cee022b0a20fc1bd8bf73f23737bdd9353e67a3ab29bb8f03b918",
user@ubuntu-4:~$ sudo docker inspect 7a4b2eed4ea9 | grep NetworkMode
"NetworkMode": "container:fdebc46bf25cee022b0a20fc1bd8bf73f23737bdd9353e67a3ab29bb8f03b918",
user@ubuntu-4:~$
At this point we’ve seen how pause containers work, how to deploy pods with one or more containers, as well as some of the limitations of multi-container pods. What we haven’t talked about is where the pod IP address comes into play. Let’s talk through that next by examining the configuration for our first pod we defined that’s living on ubuntu-3.
Once the pod IP is allocated it is assigned to the pause container. The work of downloading the containers defined as part of the pod definition and mapping them into the pause containers network namespace begins. As I hinted to in earlier posts, Kubernetes now leverages CNI to provide container networking. If you looked closely at the systemd service definition for the kubelet running on the nodes you’d see a line that defines what network plugin is being used…
user@ubuntu-3:~$ more /etc/systemd/system/kubelet.service [Unit] Description=Kubernetes Kubelet Documentation=https://github.com/GoogleCloudPlatform/kubernetes After=docker.service Requires=docker.service [Service] ExecStart=/usr/bin/kubelet \ --allow-privileged=true \ --api-servers=https://10.20.30.71:6443 \ --cloud-provider= \ --cluster-dns=10.11.12.254 \ --cluster-domain=k8s.cluster.local \ --container-runtime=docker \ --docker=unix:///var/run/docker.sock \ --network-plugin=kubenet \ --kubeconfig=/var/lib/kubelet/kubeconfig \ --reconcile-cidr=true \ --serialize-image-pulls=false \ --tls-cert-file=/var/lib/kube_certs/kubernetes.pem \ --tls-private-key-file=/var/lib/kube_certs/kubernetes-key.pem \ --v=2 Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
We can see that in this case it’s the kubenet plugin. Kubenet is the built-in network plugin provided with Kubernetes. Despite being built in it still requires the CNI components bridge, lo, and host-local. Since it uses the host-local IPAM driver we know where to look for it’s IP address allocations from our previous CNI posts…
user@ubuntu-3:~$ sudo su [sudo] password for user: root@ubuntu-3:/home/user# cd /var/lib/cni/networks/kubenet/ root@ubuntu-3:/var/lib/cni/networks/kubenet# ls 10.100.1.2 10.100.1.3 last_reserved_ip root@ubuntu-3:/var/lib/cni/networks/kubenet# root@ubuntu-3:/var/lib/cni/networks/kubenet# more 10.100.1.3 57a8f71b8c9b53280986a7cd31f2a232254eccedd941c34715dc9e1bbe205030 root@ubuntu-3:/var/lib/cni/networks/kubenet#
As we described in the previous article – the host-local IPAM driver stores IP allocations in the ‘/var/lib/cni/networks/<network name>’ directory. If we browse this directory we see that there are two allocations. 10.100.1.2 is being used by kube-dns and we know that 10.100.1.3 is being used by our first pod based on the output from kubectl above.
Since we know that the pod’s IP address 10.100.1.3, we can look at that file to get the container ID of the container using that IP address. In this case, we can see that the ID lines up with the pause container ID our pod is using…
root@ubuntu-3:/var/lib/cni/networks/kubenet# docker ps -f id=57a8f71b8c9b53280986a7cd31f2a232254eccedd941c34715dc9e1bbe205030 --no-trunc CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 57a8f71b8c9b53280986a7cd31f2a232254eccedd941c34715dc9e1bbe205030 gcr.io/google_containers/pause-amd64:3.0 "/pause" About an hour ago Up About an hour k8s_POD.d8dbe16c_pod-test-1-2033762881-d8jgv_default_2f0dbba7-13e0-11e7-ac2c-000c293e4951_6feb94cc root@ubuntu-3:/var/lib/cni/networks/kubenet#
If we look at the documentation for the kubenet plugin we’ll see it works in the following manner…
Kubenet creates a Linux bridge named
cbr0and creates a veth pair for each pod with the host end of each pair connected tocbr0. The pod end of the pair is assigned an IP address allocated from a range assigned to the node either through configuration or by the controller-manager.
If we look at the interfaces on the ubuntu-3 host we will see the cbr0 interface along with one side of a VETH pair that lists cbr0 as it’s parent…
user@ubuntu-3:~$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:78:24:28 brd ff:ff:ff:ff:ff:ff
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:94:0d:3d:f9 brd ff:ff:ff:ff:ff:ff
4: cbr0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc htb state UP mode DEFAULT group default qlen 1000
link/ether 0a:58:0a:64:01:01 brd ff:ff:ff:ff:ff:ff
5: vethf65ddc64@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether 2a:3c:d9:81:cd:87 brd ff:ff:ff:ff:ff:ff link-netnsid 0
6: vethfa911188@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether fa:ac:99:35:3f:d8 brd ff:ff:ff:ff:ff:ff link-netnsid 1
user@ubuntu-3:~$
In this case there are two VETH pair interfaces listed but we can easily tell which one belongs to our pod by checking the VETH pair mapping in the pod…
ser@ubuntu-3:~$ sudo docker exec -it 406093610e69 ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 0a:58:0a:64:01:03 brd ff:ff:ff:ff:ff:ff
user@ubuntu-3:~$
Notice that the pod believes that the other end of the VETH pair is interface number 6 (eth0@if6) which lines up with the VETH interface ‘vethfa911188@if3’ on the host. So at this point we know how pod’s are networked on the localhost. The whole setup looks something like this…
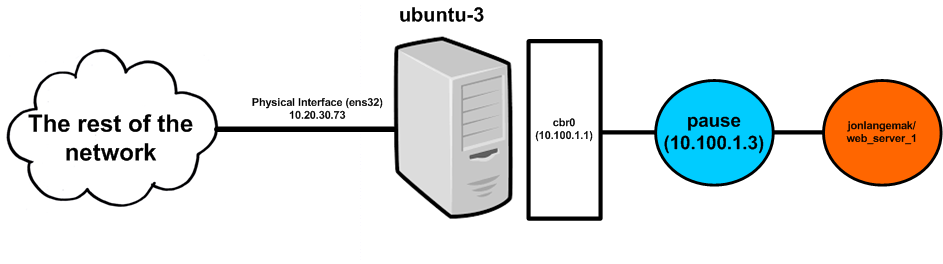
Now let’s talk about what this means from a network perspective. As part of the cluster setup we routed the 10.100.1.0/24 network to the host ubuntu-3 physical interface address of 10.20.30.73. This means that if I initiate a network request toward a pod IP address it will end up on the host. Additionally, since the host sees 10.100.1.0/24 as connected – it will attempt to ARP for any IP address in that subnet. This means that in this case (natively routed pod networks) the pods are accessible directly…
user@ubuntu-1:~$ curl http://10.100.1.3 <body> <html> <h1><span style="color:#FF0000;font-size:72px;">Web Server #1 - Running on port 80</span></h1> </body> </html> user@ubuntu-1:~$
So long as the routing is in place, I can even access the pod networks from my desktop machine which is on a remote subnet but uses the same gateway…

You’d also find that you can connect to the containers running in the third pod (10.100.2.2) in the same manner. In this case, since there are two containers we can access them on their respective ports of 80 and 8080…


Should pods be accessed this way? Not really but it is a troubleshooting step you can perform if your network routing allows for the connectivity. Pods should be accessed through services which we’ll discuss in the next post.
Awesome writeup, this is super helpful! I think there might be a slight error after you show the pod2-test.yaml you have:
“`
Notice that this specification defines two pods, jonlangemak/web_server_1 and jonlangemak/web_server_2. To have Kubernetes load this pod run the following command…
“`
Shouldn’t that be that the spec defines two containers?
Great catch! I’ve changed it to…
“Notice that this specification defines two containers, jonlangemak/web_server_1 and jonlangemak/web_server_2. To have Kubernetes load this pod run the following command…”
You mentioned that “This means that in this case (natively routed pod networks) the pods are accessible directly…”
is there a networking scenario in kubernetes where we do not update the L3 gateway with pod ranges and it would still work?
Your posts are really helping demystify networking for me
You said – “Notice that the pod believes that the other end of the VETH pair is interface number 6 (eth0@if6) which lines up with the VETH interface ‘vethfa911188@if3’ on the host. ”
How did you verify that?
Never mind, didn’t look hard enough
Hello, I am unable to determine how the interface on the pod is mapped to the correct veth interface on the bridge. Could you clarify? Thanks.
Got it now. Thanks.
This was extremely helpful. Thank you.